K-Means Clustering : 주어진 데이터를 k개의 클러스터로 묶는 알고리즘
iris2=iris[1:4]
head(iris2)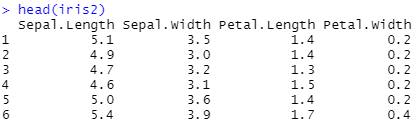
km.out.withness=c()
km.out.between=c()
for(i in 2:7){
set.seed(1)
km.out=kmeans(iris2,center=i)
km.out.withness[i-1]<-km.out$tot.withinss
km.out.between[i-1]<-km.out$betweenss
}
data.frame(km.out.withness, km.out.between)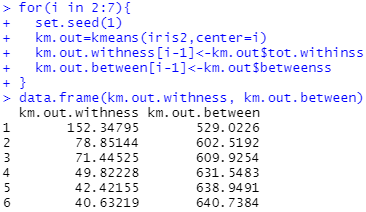
km.out.k3=kmeans(iris2,centers = 3)
km.out.k3$centers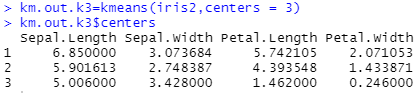
km.out$cluster
km.out.k3$size
table(km.out.k3$cluster,iris$Species)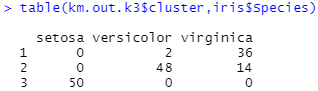
plot(iris2[,1:2],
col=km.out.k3$cluster,
pch=ifelse(km.out.k3$cluster==1,16,
ifelse(km.out.k3$cluster==2,17,18)),
cex=2)
points(km.out.k3$centers,
col=1:3,
pch=16:18,
cex=5)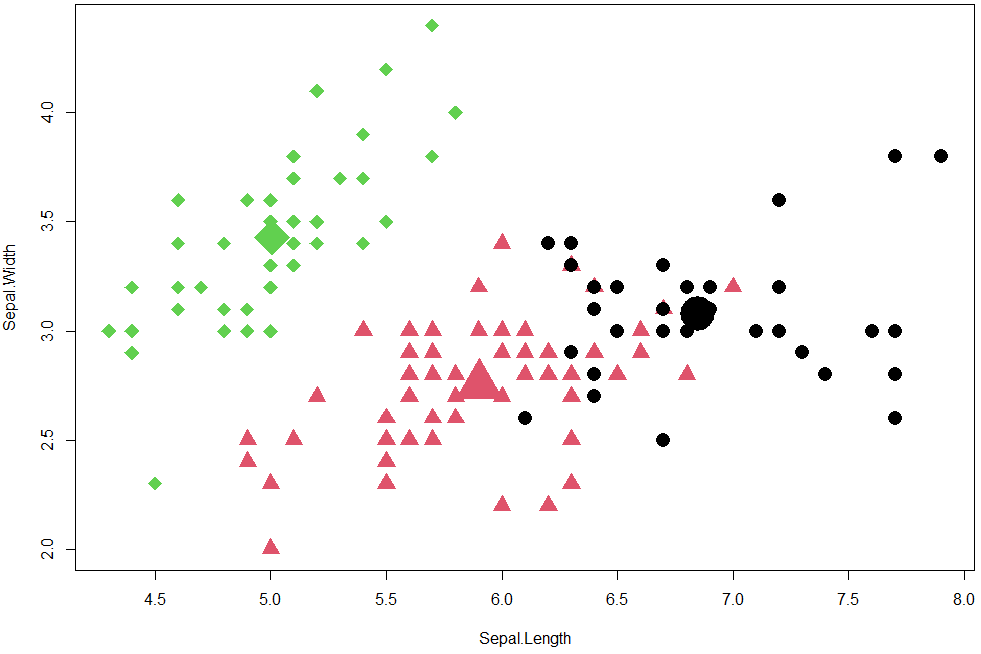
반응형
'공부합시다 > 찍먹' 카테고리의 다른 글
| [R] 연관성분석(장바구니 분석) (0) | 2021.06.15 |
|---|---|
| [R] 차원축소 기법 (0) | 2021.06.15 |
| [R] 수치 예측 목적의 러신머닝 (0) | 2021.06.15 |
| [R] 분류 목적 머신러닝 (0) | 2021.06.14 |
| [R] 데이터 세트 분할하기 (0) | 2021.06.14 |